
AI is only as good as your data.

Data With Media Title

Feature Store Design & Implementation
Consistent features at training. Consistent features in production.
Build and manage the feature pipelines that feed ML models at training and real-time inference, offline store for batch training, online store for low-latency serving. Prevents training-serving skew, one of the most common causes of model failure in production.

Vector Database & Embedding Pipeline Management
The retrieval layer your GenAI actually needs.
Infrastructure for RAG applications, semantic search, and recommendation systems, covering embedding generation, indexing, and retrieval pipelines. Without this layer, GenAI applications hallucinate. With it, they retrieve and reason accurately.

AI-Ready Data Transformation
Data built for models, not just reports.
Cleaning, chunking, schema validation, and enrichment pipelines built specifically for model consumption. The destination is AI/ML infrastructure optimized for training and inference, not just cloud storage.

GenAI Guardrails & AI Governance
GenAI without governance is a liability, not an asset.
Governance frameworks specifically designed for GenAI and AI agent deployments: hallucination prevention, compliance filters, output validation, audit logging, and explainability. Goes beyond general data governance to address AI-specific risks regulators and boards are asking about.

Data Quality for AI
Catch bad data before it reaches your models.
Automated quality checks, drift detection, and anomaly detection embedded before data reaches models, catching problems at source rather than letting them surface as unexplained model failures.
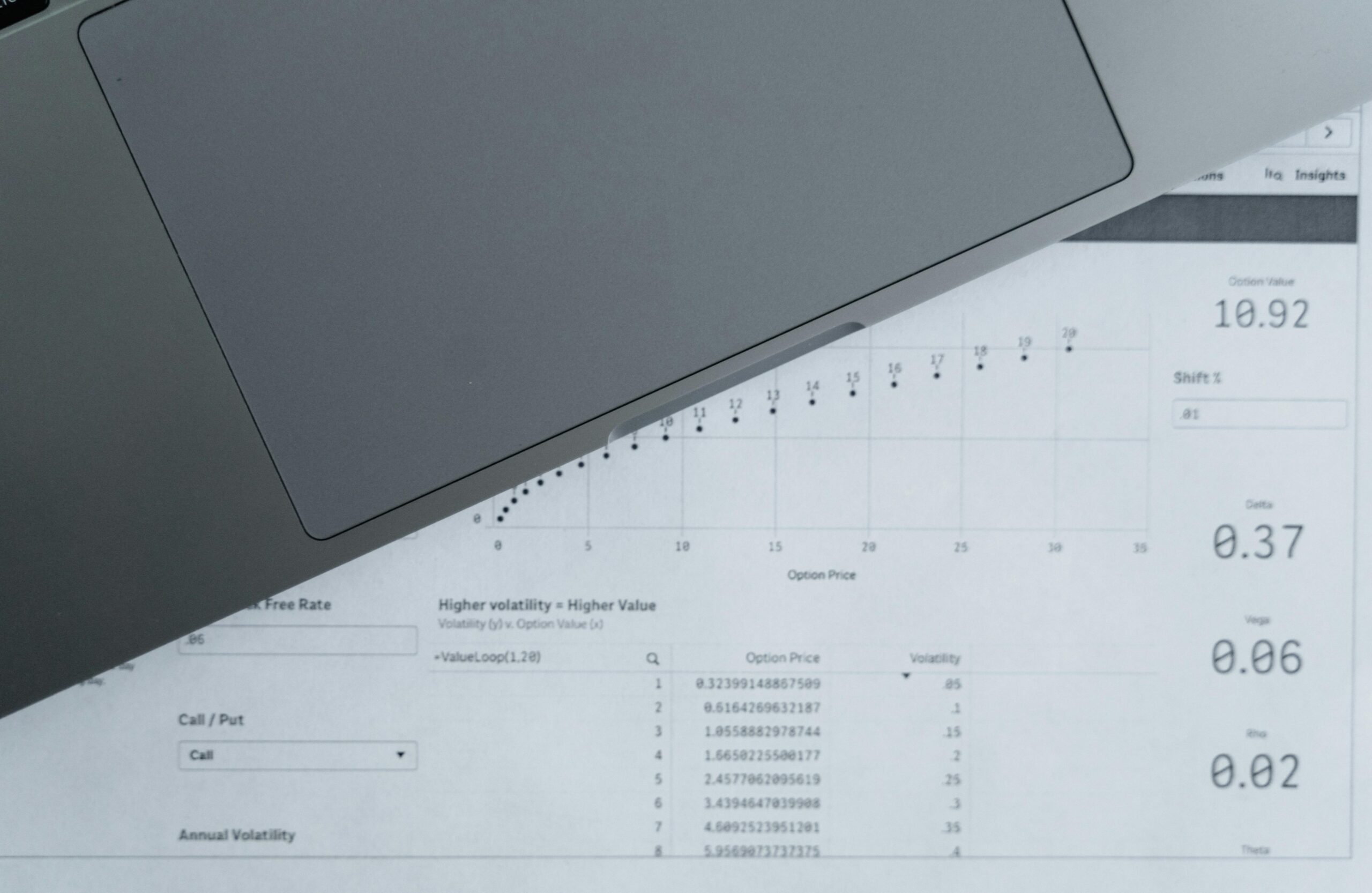
Synthetic Data Generation
When real data isn’t enough or can’t be used.
For regulated industries or where labelled training data is scarce, generating synthetic data that preserves statistical properties without exposing actual records. Enables model training in BFSI and Healthcare where real data cannot be used.
How it works
Assess
Design
Engineer
Govern
Operate
Assess
Design
Engineer
Govern
Operate
Built for your industry. Designed for AI that works.
Financial Services
Customer Data for AI
Compliance-embedded governance for regulated AI.
Financial services AI faces unique challenges: models must be explainable to regulators, training data must be auditable, and GenAI must not hallucinate on financial advice. We build AI-ready data foundations with compliance embedded, from feature stores for credit risk models to GenAI guardrails that prevent regulatory violations. Your AI that satisfies both data scientists and compliance officers.
Key Use Cases:
- Feature stores for credit risk and fraud models
- Explainability frameworks for regulatory requirements
- GenAI guardrails for customer-facing AI (no hallucinated financial advice)
- Training data preparation for propensity and risk models
- AI governance for model audit trails
Compliance-embedded — AI governance for regulators | Explainability — for model audit trails
Retail
Data for AI
AI that understands products, customers, and commerce.
Retail AI needs data that understands commerce context, product attributes, customer behaviour, inventory dynamics, and seasonal patterns. We engineer data specifically for retail AI use cases: recommendation engines, demand forecasting, dynamic pricing, and personalization models. Training data that reflects how retail actually works.
Key Use Cases:
- Feature engineering for recommendation engines
- Training data for demand forecasting models
- Data pipelines for dynamic pricing AI
- Product attribute extraction and labeling
- Real-time inference feeds for personalization
Commerce-aware — AI data for retail context | Real-time — inference-ready for personalization
Telecommunications
Customer Data for AI
AI for churn, upsell, and network optimization.
Telcos have massive data assets, subscriber behaviour, network usage, service interactions but it’s trapped in legacy BSS/OSS systems. We engineer AI-ready subscriber data for churn prediction, upsell propensity, network optimization, and data monetization.
Key Use Cases:
- Feature stores for churn and upsell models
- Data engineering from BSS/OSS systems for AI
- Training data for network optimisation AI
- Real-time inference pipelines for next-best-action
Scale-ready — high-volume telco data for AI | Real-time — inference pipelines for activation
Customer Stories



How a Global Media Group Built AI-powered Creative Generation with Governed Data



