Vibe Coding in 2026: The Honest Guide for Developers Who Actually Ship Things
Let me be upfront about something: I was skeptical of vibe coding for longer than I should have been.
The name didn’t help. “Vibe coding” sounds like something a startup founder says right before they demo a product that crashes. And the early discourse around it was exhausting — half the takes were “AI will replace developers,” the other half were “this is just fancy autocomplete,” and both camps were missing what was actually interesting about it. What changed my mind wasn’t a blog post. It was watching a project manager on my team — someone who could barely write a api call — build a working internal dashboard in an afternoon using Claude Code. Not a perfect dashboard. Not one I’d put in front of customers. But real, functional, connected to our actual database, doing useful things. That took me a while to process.
So here’s what vibe coding actually is, what it’s good for, and where it will quietly wreck your project if you’re not paying attention.
The core shift is about where your mental energy goes. Normal development forces you to hold two things in your head at once: what you’re trying to build and how to express it in code. Those are genuinely different cognitive tasks, and switching between them constantly is expensive — it’s part of why programming is tiring in a way that’s hard to explain to non-programmers.
Vibe coding offloads the “how” to a model. You stay in the “what.” That’s the whole thing, really. The rest is details.
Andrej Karpathy named it in early 2025, describing it as a mode where you guide AI through a conversational loop rather than writing implementation yourself. The framing caught on because it described something people were already experiencing but hadn’t articulated. Not because it was new, exactly — developers have been using AI autocomplete for years — but because the capability had crossed some threshold where the workflow genuinely changed.
Here’s the part that took me a while to internalize: vibe coding doesn’t eliminate bugs, it changes what kind of bugs you get. Traditional coding gives you implementation bugs — off-by-one errors, null pointer exceptions, that kind of thing. Vibe coding mostly eliminates those. What you get instead are specification bugs: you described something slightly wrong, the model interpreted it literally, and now you have technically correct code that does the wrong thing. That’s actually harder to catch if you’re not looking for it.
Here’s the loop everyone describes: prompt → generate → test → refine → repeat. Fine. That’s accurate but not very useful on its own. What’s more useful is knowing exactly where each stage goes sideways.
Stage 1 — Intent
The quality of everything downstream depends on how clearly you describe the goal. Not just what you want, but what you explicitly don’t want, what constraints apply, and what “this is working correctly” looks like. Vague goals produce code that’s technically plausible but wrong in ways that are annoying to diagnose.
Stage 2 — Generation
Don’t just run it. Read it first. I know that sounds obvious but most people skip this step because the code looks reasonable and they’re in a hurry. Look specifically for: hardcoded values that should be config, library choices you didn’t intend, error handling that silently swallows failures, and anything that looks like the model made an assumption about your infrastructure.
Stage 3 — Execution and observation
Run the happy path, then immediately break it. Empty inputs. Null values. What happens when the third-party service returns a 503? What does the error actually look like to whoever’s calling this? I’ve seen a lot of vibe-coded APIs that return a 200 with an error message in the body. That’s a choice. Probably not the one you wanted.
Stage 4 — Feedback
This is where most people leave a lot on the table. “It’s broken, fix it” is not a useful prompt. What you said, what happened, and what you expected are three different things — give the model all three. “The endpoint returns HTTP 200 when the record doesn’t exist. It should return 404 with a JSON body containing an error field and a human-readable message.” That gets fixed in one pass. “It’s broken” starts a negotiation.
The doom loop
You’ll know you’re in it when the model fixes one thing and breaks another, and you’ve been going back and forth for 45 minutes on what should have been a 10-minute problem. This happens for two reasons. Either your original spec was ambiguous enough that the model made structural assumptions that are now load-bearing, or the conversation has gotten long enough that earlier context is getting dropped from the window.
The fix — and I say this from experience of not doing it for too long — is to stop, write a clean summary of where things stand, and start a fresh session. It feels like giving up. It’s almost always faster.
The leverage here is enormous. A mediocre prompt and a good prompt can produce outputs that are genuinely miles apart.
Lock in your environment upfront
The model doesn’t know your stack unless you tell it. And if you don’t tell it, it’ll guess — usually toward whatever is most common in its training data, which may not be what you’re using.
What works:
“Node.js 20, Express, TypeScript in strict mode. Raw SQL via the pg library — no ORMs. Route handlers should be thin; business logic goes in a separate service layer.”
What produces something generic you’ll have to rewrite:
“Make me an API.”
Describe what users do, not how code should work
Tell the model what the system should do from the perspective of someone using it, then let it figure out implementation. If you describe the implementation, you’re just dictating code through a slower interface.
“When someone submits a job application, the system should reject files that aren’t PDFs or exceed 5MB, store accepted files in object storage, and trigger an async notification to the recruiter. Every failure mode should return a structured error — no silent swallowing.”
Tell it what’s off-limits
Negative constraints are underused and very effective. The model responds well to explicit prohibitions.
“This endpoint has no authentication. Never trust anything in the request body for permission decisions. Resolve the user’s access rights server-side from the session token only. I don’t care how the caller says they’re authorized.”
Ask it to rat itself out
Before running anything non-trivial, ask the model to flag its own decisions:
“Before I run this — what assumptions did you make that I should know about? Specifically around error handling, anything stateful, and anything that’ll behave differently locally versus in production.”
You will catch things this way. Not every time, but often enough that it’s worth the habit.
Context files — use them, seriously
Most AI coding agents support a persistent context file in your repo root. Claude Code uses CLAUDE.md, Gemini CLI uses GEMINI.md, Cursor has its own version or the latest one rules all AGENTS.md. This file gets loaded with every session. If you don’t have one, you’re re-explaining your entire stack at the start of every conversation like some kind of groundhog day for developers.
Mine for a recent Go project looked like:
Stack: Go 1.22, Chi router, PostgreSQL 16, Redis for caching
Error handling: Always return errors explicitly. No panic outside of main().
Logging: Structured only, via slog. No fmt.Println anywhere in production paths.
SQL: Parameterized queries. Always. I don’t want to see string formatting in a query ever.
Testing: Table-driven tests. Use testify/assert. Mock external dependencies.
Takes 20 minutes to write. Saves that 20 minutes on every subsequent session.
Build in layers, review at each one
For anything non-trivial, don’t ask for the whole feature at once. Ask for the data model. Review it. Ask for the service layer. Review it. Ask for the API handlers. Review those. Each layer is a checkpoint. Misalignments caught at the data model layer cost almost nothing to fix. Misalignments caught after you’ve wired everything together cost a lot.
Type contracts first
For anything that crosses a boundary — API responses, event payloads, database schemas — ask for the type definitions before any implementation. In TypeScript, that’s interfaces or Zod schemas. In Go, structs with json tags. In Rust, the type system handles this almost automatically. Having a firm contract before implementation prevents a whole category of bugs that are genuinely unpleasant to track down.
Tests at the same time, not after
Ask for unit tests alongside the implementation, not as a follow-up. When the model writes both together, the tests tend to reflect what the code is supposed to do. Tests added after the fact tend to just describe what the code does — which is less useful and sometimes outright wrong.
Pin your dependencies
The model will reach for latest if you don’t specify. This is fine until it isn’t. Specify major versions for anything where stability matters, either in a context file or directly in the prompt. I’ve been burned by this. Generated code using a library API that changed in the past three months is annoying to debug when you don’t know that’s the problem.
All-in-one platforms — Lovable, Bolt, Replit
Fast. No setup. Good for validating whether an idea is worth pursuing before you commit to building it properly. The tradeoffs: you’re in their environment, extraction is harder than advertised, and — this is real — recent security research found thousands of apps on these platforms accidentally exposing sensitive data because the default visibility settings weren’t what users assumed. Not a reason to avoid them. A reason to understand what you’re deploying before you deploy it.
Terminal agents — Claude Code, Gemini CLI
These live in your actual project. They understand your file structure, can run commands, and operate in your environment rather than theirs. Harder to start with, much better for real work. This is what I use for anything that needs to be maintained.
IDE tools — Cursor, Cody
These sit inside your editor and help at the file level. Less about driving end-to-end generation, more about making your existing workflow faster. Good if you want AI assistance without changing how you fundamentally work.
My honest take: start with an all-in-one platform if you’re exploring something new and have no existing codebase. Move to an agent when you’re building something real.
Security
This one keeps me up at night a little. The model was trained on a lot of code. Including a lot of insecure code. Patterns like JWTs in localStorage, missing authorization checks on internal routes, CORS configs that are technically “works” but shouldn’t — these show up in generated code because they’re common in training data. Anything with a security surface needs a human review from someone who knows what bad looks like.
Performance
The model optimizes for “works and is readable” before it optimizes for fast. That’s usually the right priority for a prototype. It’s the wrong priority for a high-throughput pipeline or a latency-sensitive endpoint. The model can help you understand where bottlenecks are. It won’t automatically write cache-efficient code or think carefully about memory allocation.
Architectural consistency over time
This one sneaks up on you. Each individual piece of generated code might be reasonable. But across many sessions, patterns drift. One module handles errors one way, another does it differently. Nobody enforced consistency because nobody was thinking across sessions. For a prototype, who cares. For something you’ll modify in six months — you’ll care. You’ll care a lot.
Concurrency and distributed systems
Race conditions are hard for humans to reason about. They’re harder for models. Generated concurrent code tends to handle the obvious paths and miss the subtle failure modes. I wouldn’t trust vibe-coded distributed logic without a very careful manual review. This is not where you save time.
The developers I’ve seen get the most out of vibe coding are not the ones who use it to avoid understanding what they’re building. They’re the ones who already understand software systems reasonably well, and use vibe coding to move faster on the parts that don’t require their judgment.
That’s a different story than “anyone can build anything now.” Both things can be true: the barrier to getting something working is genuinely lower, and your ability to build something good still depends heavily on your ability to recognize when what you got isn’t good enough.
What does change — and this part I think is underappreciated — is the cost of being wrong. When a prototype takes four hours instead of four days, you can try more ideas, kill bad ones faster, and spend your real effort on the problems that actually need you.
That’s not nothing. That’s actually a lot.
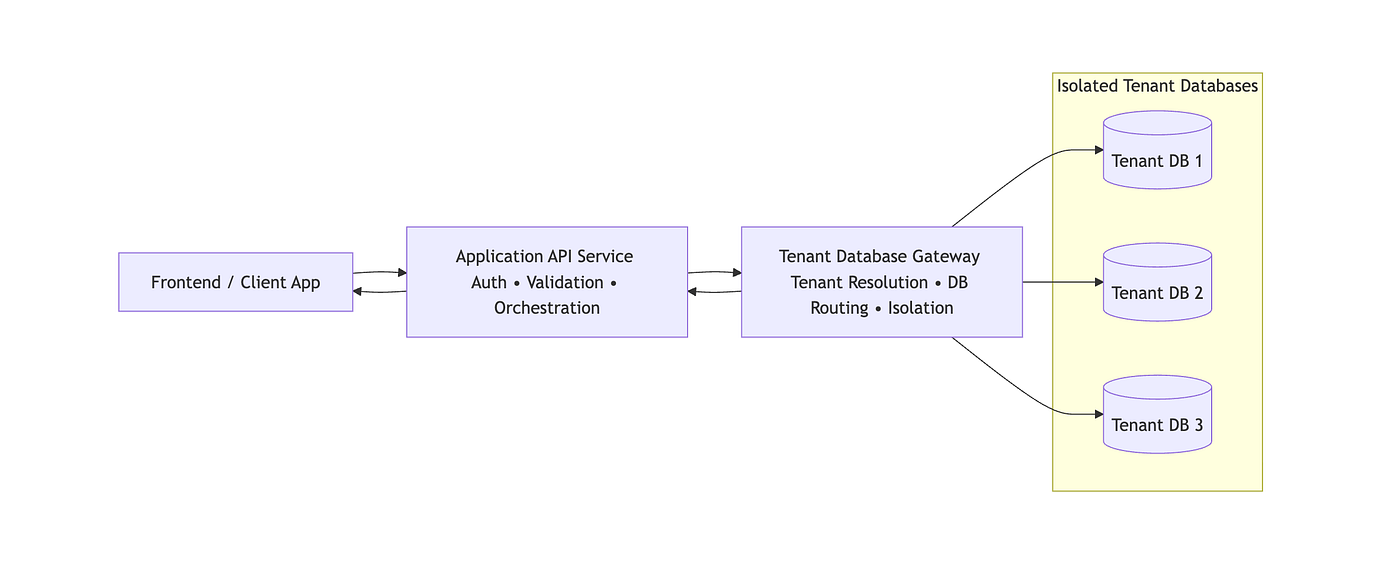
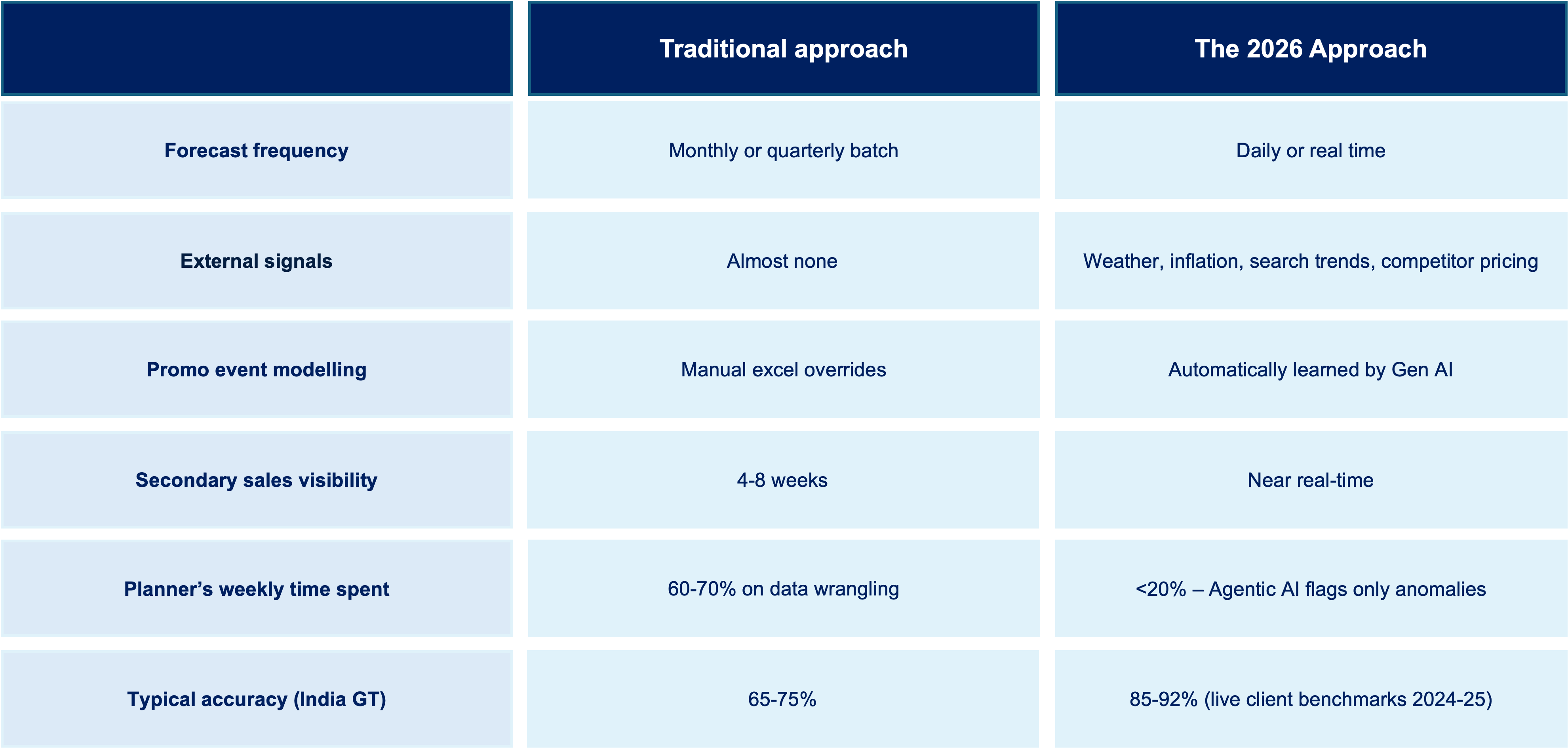
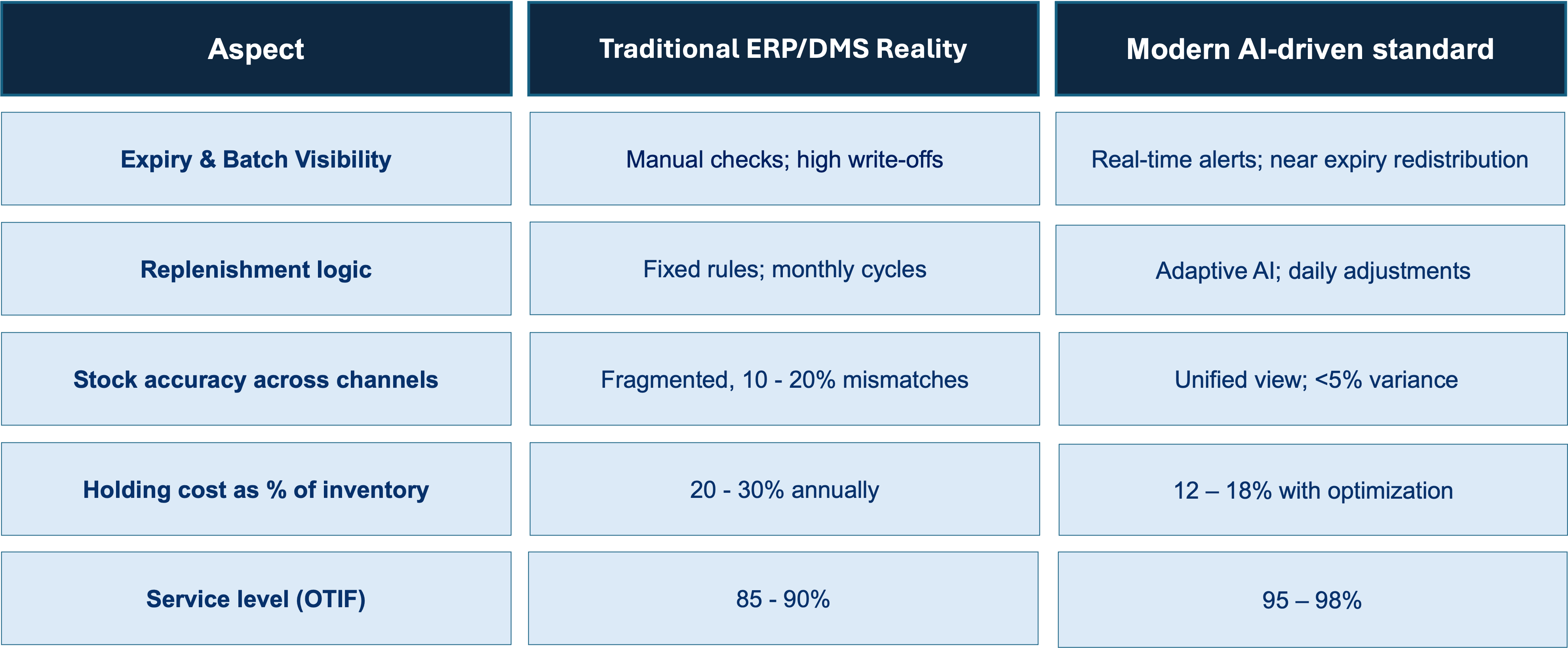
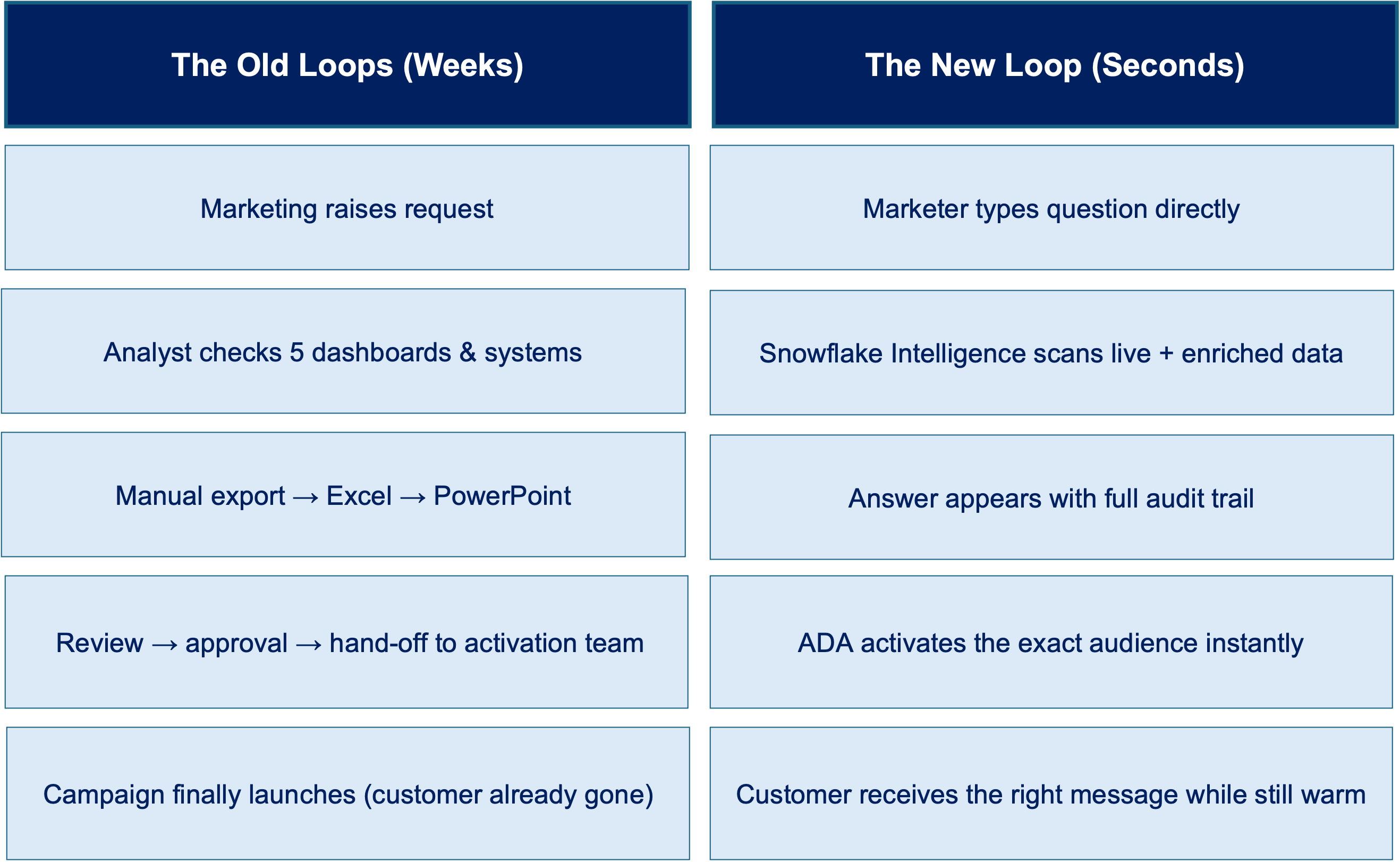
Scaling beyond the “vibe” while “vibe coding” allows us to prototype at lightning speed, moving from a cool prototype to an enterprise-grade application requires robust data architectures and secure deployment pipelines. To truly unlock the business value of these AI-generated systems, organizations are partnering with end-to-end digital transformation experts like ADA Global to integrate advanced data engineering, AI analytics, and scalable cloud infrastructure.








.png)
.png)


.png)


